パーティクルフィルタは,時系列フィルタの一種で,マルコフ決定過程(現在の状態は一個前の状態にのみ依存するモデル)のもとで,任意の形をした事前確率分布をモンテカルロ法で近似して,事後分布を推定する手法です(雑).
関連するものとして,カルマンフィルタは事前分布事後分布ともにガウス分布を仮定するモデルで,平均と分散をそれぞれ推定するモデルです.パーティクルフィルタは,ガウス分布ではない(よくわからない)分布のときに有効です.
基本的な処理の流れは,何か推定したい変数の分布があるときに,①一つ前の時刻での分布を複数のサンプルで表現,②各サンプルの変化(時間発展)を計算,③各サンプルが現在時刻での観測にどれだけ合っているか(尤度)を計算,④尤度に応じてサンプルを再サンプリング(リサンプリング),です.
①は,例えば100個の点の集まりで,分布を表現します.
②は,各サンプルについて,時間発展の計算(予測)をします.例えば,物体の位置を追跡したいがどっちに動くかは分かっていない場合,物体の移動量はガウス分布に従うと仮定して,\(x_{t} = x_{t-1} + \epsilon, \;\;\epsilon\sim\mathcal{N}\)とします.
③では,時間発展させた各サンプルと,現在時刻での観測値とを使って,各サンプルの尤度を計算します.例えば,観測値と推定値がどれだけ近いか,推定した位置の画素値と追跡対象の色がどれだけ似ているか,などが使われます.
④では,尤度の大きさに応じて,時間発展させたサンプルを生き残らせるかどうかを判定します.重複を許した選択(尤度が高いほど選ばれやすい)を行い,最終的に,もとのサンプル数と同じ数のサンプルを選択して,現在の分布の近似とします.
出力としては,時間発展させたサンプルの値を,尤度で重み付け平均をとったものを使います.(数式上はそうですが,実際は尤度の高いサンプルだけの平均を取ったほうが外れ値にロバストになります)
以上の処理をPythonでできるだけ効率的な処理となるように実装してみました.Pythonではfor文を使うと遅いので,Particle Filter内ではfor文を使わずに実装しています.この例では,1000個のパーティクルで確率分布を近似するようにしています.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import random
import cv2
# from icecream import ic
class TransitionModel(object):
def __init__(self):
pass
def predict(self, current):
# 単純に分散2の範囲で移動するモデル
s = current.shape
return current + np.random.randn(s[0], s[1]) * 2
class ObservationModel(object):
def __init__(self):
pass
def likelihood(self, predictions, observation):
# 単純に,差の指数関数の逆数を尤度とするモデル(0割が起きなくて,良いサンプルほど高い値になるような関数なら何でも良い)
return 1 / np.exp(np.mean(np.power(predictions - observation, 2), axis=1))
class ParticleFilter(object):
def __init__(self, num_particle, n_dims, trans, observ, initial=None):
self.num_particle = num_particle
self.trans = trans
self.observer = observ
if initial is None:
self.particles = np.zeros((num_particle, n_dims))
else:
self.particles = initial
def update(self, obs):
# 前フレームからの予測
predictions = self.trans.predict(self.particles)
# ic(predictions)
# 予測がどれだけ現在の観測に合致しているかの評価
likelihoods = self.observer.likelihood(predictions, obs)
# ic(likelihoods)
# 尤度に応じてリサンプリング
self.resampling(predictions, likelihoods)
# likelihoodsで重み付けられたpredctionsの平均をとる
return np.average(predictions, weights=likelihoods, axis=0)
def resampling(self, predictions, likelihoods):
# 正規化した累積和を計算(全部足して1になるように)
slikelihoods = np.cumsum(likelihoods) / np.sum(likelihoods)
self.particles = np.array(random.choices(predictions, cum_weights=slikelihoods, k=self.num_particle))
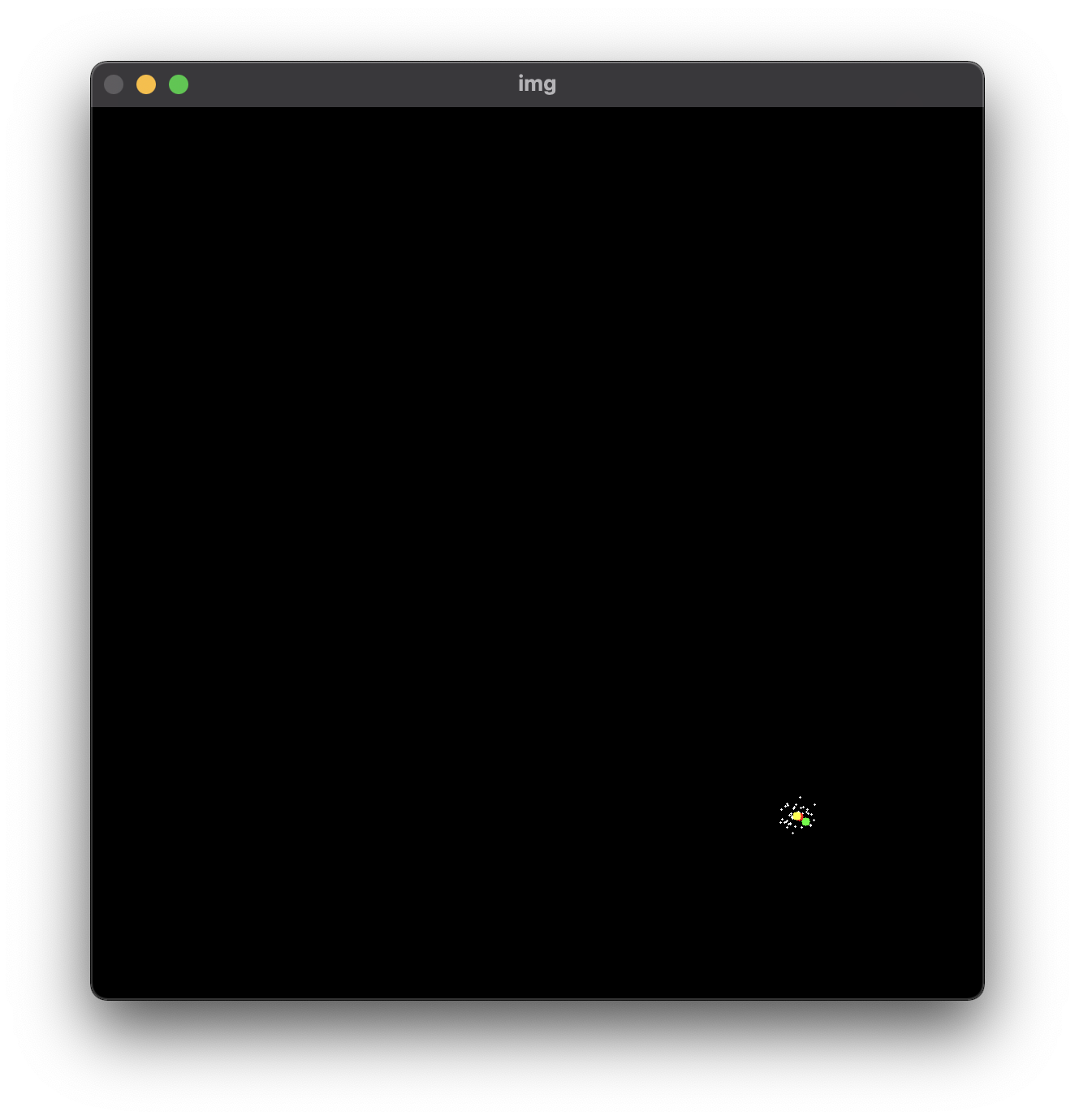
def visualize(x, o, p, ps):
img = np.zeros((1100, 1100, 3), dtype=np.uint8)
for particle in ps:
cv2.circle(img, (int(particle[0] * 10) + 50, int(particle[1] * 10) + 50), 1, (255, 255, 255), -1)
cv2.circle(img, (int(x * 10) + 50, int(x * 10) + 50), 5, (0, 255, 0), -1)
cv2.circle(img, (int(o[0] * 10) + 50, int(o[1] * 10) + 50), 5, (0, 0, 255), -1)
cv2.circle(img, (int(p[0] * 10) + 50, int(p[1] * 10) + 50), 5, (0, 255, 255), -1)
return img
if __name__ == "__main__":
# 100パーティクルで近似,2次元の状態ベクトル(観測と次元数が違っても良い(ObservationModelで評価方法を実装))
trans = TransitionModel()
observ = ObservationModel()
pf = ParticleFilter(1000, 2, trans, observ)
for x in range(100):
# (x, x)が真の値
# 誤差が乗っている観測データ
o1 = x + np.random.randn()
o2 = x + np.random.randn()
o = [o1, o2]
# パーティクルフィルタによる推定
p = pf.update(o)
img = visualize(x, o, p, pf.particles)
cv2.imshow("img", img)
cv2.waitKey(100)
print("observation: ({}, {}), truth: ({}, {}), estimation: ({}, {})".format(o[0], o[1], x, x, p[0], p[1]))
for x in range(100, 0, -1):
# 誤差が乗っている観測データ
o1 = x + np.random.randn()
o2 = x + np.random.randn()
o = [o1, o2]
# パーティクルフィルタによる推定
p = pf.update(o)
img = visualize(x, o, p, pf.particles)
cv2.imshow("img", img)
cv2.waitKey(100)
print("observation: ({}, {}), truth: ({}, {}), estimation: ({}, {})".format(o[0], o[1], x, x, p[0], p[1]))
今回パーティクルフィルタがよく使われる物体追跡で説明しましたが,物体位置を推定する以外にも,推定したい値が時間的に変化していて,それの観測が得られている状況なら色々と使えます.
ちなみに,画像中の物体追跡という文脈では,CONDENSATION( CONditional DENSity propagATION)と呼ばれ,OpenCVなどでも実装されています.